

How to Maximize the Value of Artificial intelligence and Machine Learning
ML Works
ML Works is an end to end machine learning model management accelerator enabling MLOps at scale, from model generation, orchestration, and deployment, to monitoring, health, diagnostics, governance, and business metric tracking. It enables white-box model deployment and monitoring to ensure complete provenance review, transparency, and explainability of model.
Solutions
Why ML Works?
With the current business challenges and uncertainty, it has become imperative that AI/ML models driving an organization’s business decisions continue to do so effectively. In today’s ever-changing landscape, model and data drift are both very real, and AI/ML models thus need to be monitored on a real-time basis to ensure they stay relevant. When ML models fail in live production, not only do they require valuable data scientists time to fix and redeploy them, they also disrupt the organization’s day to day operations and put it at risk of lapsing on regulatory requirements.
The ML Works accelerator provides customers with a visual provenance graph for an end to end model visibility and pipeline traceability, as well as persona-based dashboards to make real-time model monitoring easy for all personas from Data Engineers to business users. It also allows continuous monitoring of production models for accuracy and relevance, with auto-triggered alerts in the event of model and data drift.

Our Differentiators
MLOps Graph
Visual Provenance graph for an end to end model visibility and pipeline traceability, allowing easy troubleshooting of production issues and root cause analysis
Person-Based Dashboards
Relevant metrics for Business users, Data scientists, ML engineers, and Data engineers, with a person-based monitoring journey to make monitoring easy for all persons
Model and Data Drift Analysis
Analysis of data and model drift with auto-triggered alerts, enabling continuous monitoring of production models for accuracy and relevance
Lineage Tracking
Provenance review from dashboard metrics all the way back to base models, ensuring full visibility into model operations, including training data
Governance and Support
Centralized access control, traceability and audit logs to manage multiple user persons & ensure regulatory compliance across platforms, as well as maintenance and uptime governance through an SLA driven response and resolution process
Platform-Agnostic Advisory and Development
Cross-platform and open source setup and support models to cater to myriad business requirements
Exploring Common Challenges
ML models that go into production need to handle large volumes of data, often in real-time. Unlike traditional technologies, AI and ML deal with probabilistic outcomes – in other words, what is the most likely or unlikely result.
Therefore, the moving parts of the ML model need close monitoring and swift action when deployed to ensure accuracy, performance, and user satisfaction.
Data scientists must grapple with three key influencing factors to ensure the proper development of ML models:
- Data quality: Data can come from various sources in different volumes and formats. Since ML models are built on data, the quality, completeness, and semantics of data is critical in production environments.
- Model decay: In ML models, data patterns change as the business environment evolves. This evolution leads to a lower prediction accuracy of models trained and validated on outdated data. Such degradation of predictive model performance is known as concept drift, which makes creating, testing, and deploying ML models challenging.
- Data locality: Data locality and access patterns are used to improve the performance of a given algorithm. However, such ML models might not work correctly in production due to the difference in the quality metrics.
These factors push ML practitioners to adopt a ‘change anything, change everything’ approach – but this often leads to more problems.
Data-science teams waste time and effort navigating technology and infrastructure complexities. Costs increase due to communication and collaboration issues between engineering and data-science teams, and because of the trade-off between achieving business goals and providing stable and resilient infrastructure platforms, projects slow. On average, it could take between three months and a year to deploy ML models due to changing business objectives that require changes to the entire ML pipeline.
Finding a Solution
ML needs to evolve to tackle these challenges. Data and analytics leaders have to look for repeatable and scalable standalone software applications. In other words, enterprise leaders must rely on machine learning operations, or MLOps.
MLOps help organizations achieve automated and reliable ML model deployment, consistent model training, model monitoring, rapid experimentation, reproducible models, and accelerated model deployment. Enterprise leaders can only achieve these benefits through continuous and automated integration, delivery, and training.
MLOps Best Practices
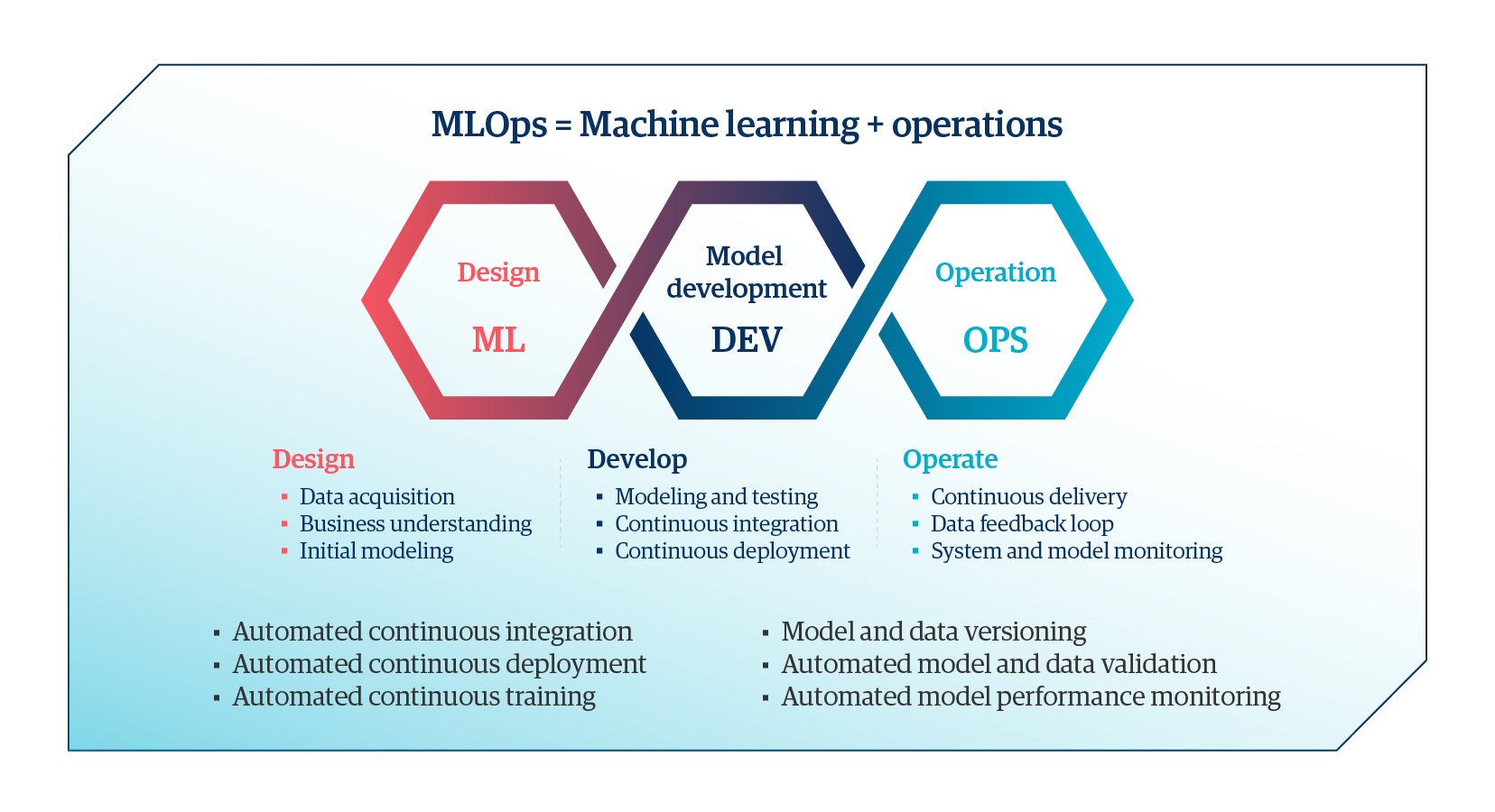
Exploring the Benefits
The implementation of MLOps in the enterprise helps align business and technology strategies, and delivers multiple benefits such as:
- Rapid innovation: Faster, effective collaboration among teams and accelerated model development and deployment will lead to rapid innovation, enabling speed-to-market
- Consistent results: Repeatable workflows and ML models will support resilient and consistent AI solutions across the enterprise
- Increased compliance and data privacy: Effective management of the entire ML lifecycle, data, and model lineage will optimize spending on data privacy and compliance regulations
- High return on investment: Management systems for ML models and model metrics will lead to smarter spending on viable use cases to avoid implementation failures
- A data-driven culture: IT and data asset tracking with improved process quality will foster a data-driven culture powered by augmented intelligence
Bringing MLOps to Life - Getting Started
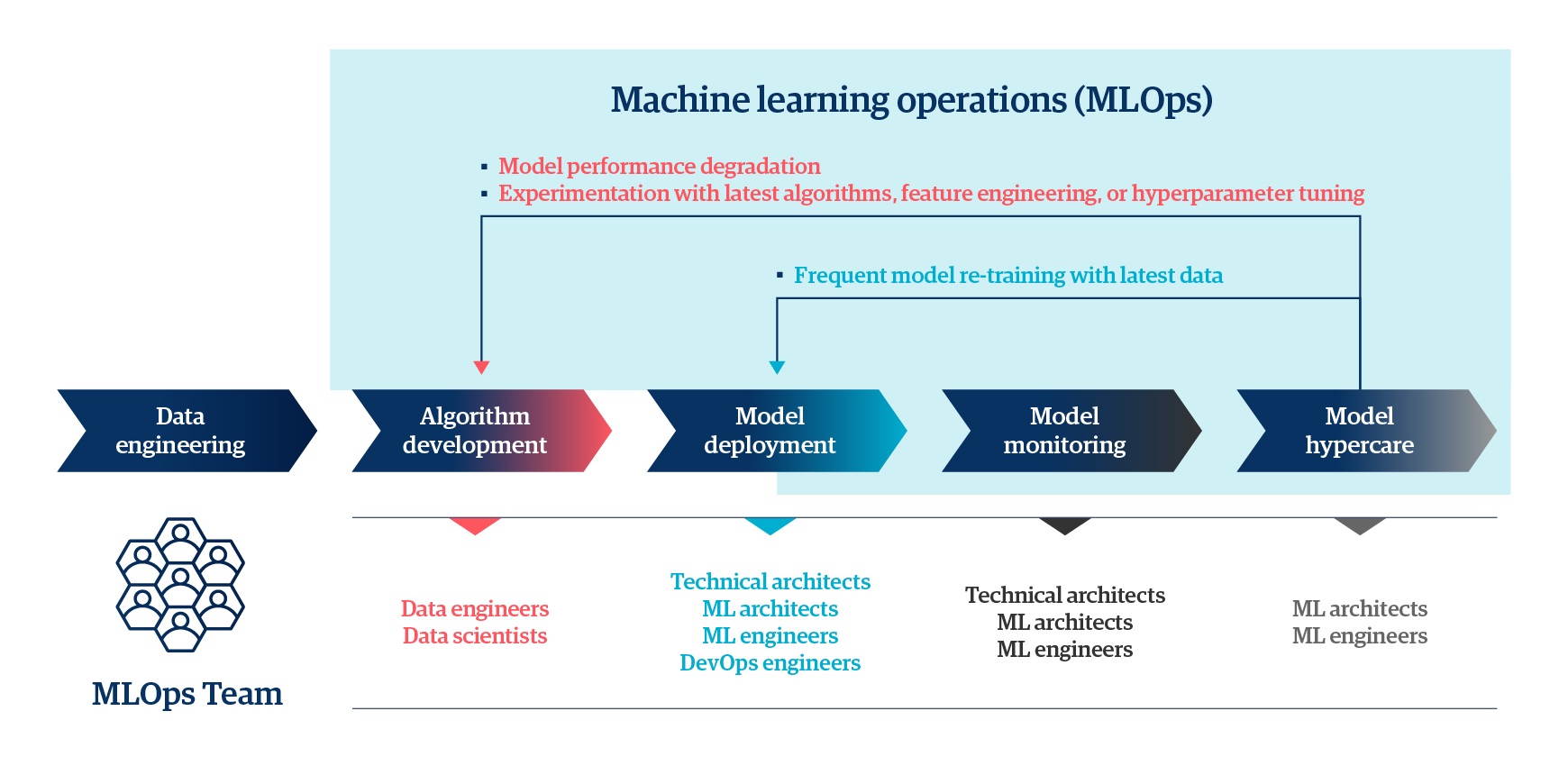
The benefits of MLOps can be seen in every industry as enterprises aspire to become increasingly data-driven. So, how do you develop MLOps in your enterprise? It starts with five steps:
- Data engineering
- Algorithm development
- Model deployment
- Model monitoring
- Model hypercare
Nevertheless, several factors – such as changes in business environments, unstandardized data collection, and unstable legacy systems, among others elements – lead to frequent changes in ML models. These changes often result in frequent re-deployments in live production environments, which are both inefficient and disruptive. On the other hand, when enterprise leaders effectively implement MLOps from the start of each project, the entire ML model lifecycle is streamlined.
MLOps as an Integral Part of ML Model Lifecycle
ML Specific Challenges
Data and Hyper-Parameters Versioning
In the traditional software application, code versioning tools are used to track changes. Version control is a prerequisite for any continuous integration (CI) solution as it enables reproducibility in a fully automated fashion. Any change in source code triggers the CI/CD pipeline to build, test and deliver production-ready code. In Machine Learning, output model can change if algorithm code or hyper-parameters or data change. While code and hyper-parameters are controlled by developers, change in data may not be. This warrants the concept of data and hyper-parameters versioning in addition to algorithm code. Note that data versioning is a challenge for unstructured data such as images and audio and that MLOps platforms adopt unique approaches to this challenge.
Iterative Development and Experimentations
ML algorithm and model development is iterative and experimental. It requires a lot of parameter tuning and feature engineering. ML pipelines work with data versions, algorithm code versions and/or hyper-parameters. Any change in these artefacts (independently) trigger new deployable model versions that warrant experimentation and metrics calculations. MLOps platforms track the complete lineage for these artefacts.
Testing
Machine Learning requires data and model testing to detect problems as early in the ML pipeline as possible.
- Data validation – check that the data is clean with no anomalies and new data is conformant to the prior distribution.
- Data preprocessing – check that data is preprocessed efficiently and in a scalable manner and avoid any training-serving skew.
- Algorithm validation – track classification/regression metrics based on the business problem as well as ensure algorithm fairness.
Security
ML models in production are often part of a larger system where its output is consumed by applications that may or may not be known. This exposes multiple security risks. MLOps needs to provide security and access control to make sure outputs of ML models is used by known users only.
Production Monitoring
Models in production requires continuous monitoring to make sure models are performing per expectation as they process new data. There are multiple dimensions of monitoring such as covariate shift, prior shift, among others.
Infrastructure Requirement
ML applications need scale and compute power that translates into a complex infrastructure. For example, GPU may be necessary during experimentations and production scaling may be necessary dynamically.